Writing Policies in Markdown
Introduction
As I set up insurance for my company, I was surprised to see very detailed questions about the implementation of information security policies, standards, and procedures. Some specific controls were included as well, such as Data Loss Protection (DLP).
Even though at the time I was reviewing the contract and filling out the form, I hadn’t implemented everything. So far, this is a one person company, so it didn’t seem like a priority.
I can’t complain that this is being asked from me, as this means it’s likely that many companies are facing these questions and are likely paying higher premiums if they indicate that they lack maturity in this space. This is one subject matter that I have expertise in. Though, I admit, it’s not my favorite. I’m an engineer at heart and sometimes even pull out the soldering iron for my home automation projects (using cheap, simple MCUs and OpenRTOS).
Information Security Policies should not be seen as just a check-the-box activity. If you really want to protect your customer’s data and your brand reputation, they are the cornerstone of an Information Security program. They provide a map of where your organization intends to be maturity-wise and should be useful both top-down (executives and middle management) and bottom up (engineers and technology practitioners).
Policies and Standards in a Nutshell
A comprehensive Information Security program starts with the definition of policies and standards. Policies are the higher level principals to be followed by an organization. Standards are the rules to which the organization adheres.
The organization looks to the program for overall responsibility to ensure the selection and implementation of appropriate security controls and to demonstrate the effectiveness of satisfying their stated security requirements. - NIST SP 800-100
This is all I’m going to cover at this time, though. I want to get on to more interesting things for an engineer-minded person.
Authoring in Markdown
This blog and the Denizen Security (DenSec) website is authored using Markdown and Hugo. As someone who first used an Emacs-like editor on an Atari 800XL for word processing, it’s a bit of a throwback for me. When it comes down to it, any of the conventions for documentation that you’ll want to use for policies and standards is available in Markdown. While the WYSIWYG experience was ground-breaking for adoption of advanced word processing, any work I do for a company is about the content, of course, not fussing with formatting.
As an engineer, I always look to eliminate repetitive tasks. When you find yourself doing something twice in your code, your impulse is to create a function. This is how I want to think of even my documentation work.
I’ll avoid getting into a Markdown tutorial. If you’re curious, follow the link provided above.
Write Once, Render N
Using a tool called Pandoc I render my policies into Microsoft Word documents (docx). To get the style I want (heading text colors, indentations, font size, font-face), I’m able to pass in a template document. See section 3.4 on the Pandoc Demo Site where you can try it yourself. I have to fuss with style only once as I set up this template document.
I’m also able to pass an argument to Pandoc which generates a table of contents.
I can render into many different formats from the Markdown. If you’re publishing to a website, I can create HTML5 or even ReactJS. For every 1 standard.md file, I can output standard.docx, standard.pdf, standard.odt, standard.html, etc.
The Business World Runs on MS Excel
As much as it pains some, Excel isn’t just for the finance department. Playing the role of enterpise architect, I’ve seen it used in every department. In Information Security, this tends to be how you do control mapping, budget-planning, etc.
Because my current client had already started writing his standards in Excel, my work was to extract this data and output Markdown. We continued to draft the language in a very organized hierarchy across cells and rows:
| 1 | 2 | 3 | 4 |
|---|---|---|---|
| Section Heading 1 | |||
| Section Heading 2 | |||
| Section Heading 3 | |||
| Section Heading 3 (and text with bullets) |
To process this, I considered many options that I have in my skill set. I know Perl and Python quite well. These would be excellent options. However, a couple of factors led me to PowerShell: the client company is very Miccrosoft oriented and also uses Azure (turning this into an Azure Function to integrate into a pipeline would be quite easy).
PowerShell can work directly with Excel as an object (with many objects within). If you have it installed, there’s no need to install any special libraries as would be the case with Perl, Python or other non-native options.
The following code (only a snip for now, I’ll post it to GitHub publicly later) iterates through the cells and rows and outputs the contents into the file indicated by Outfile or browsed to:
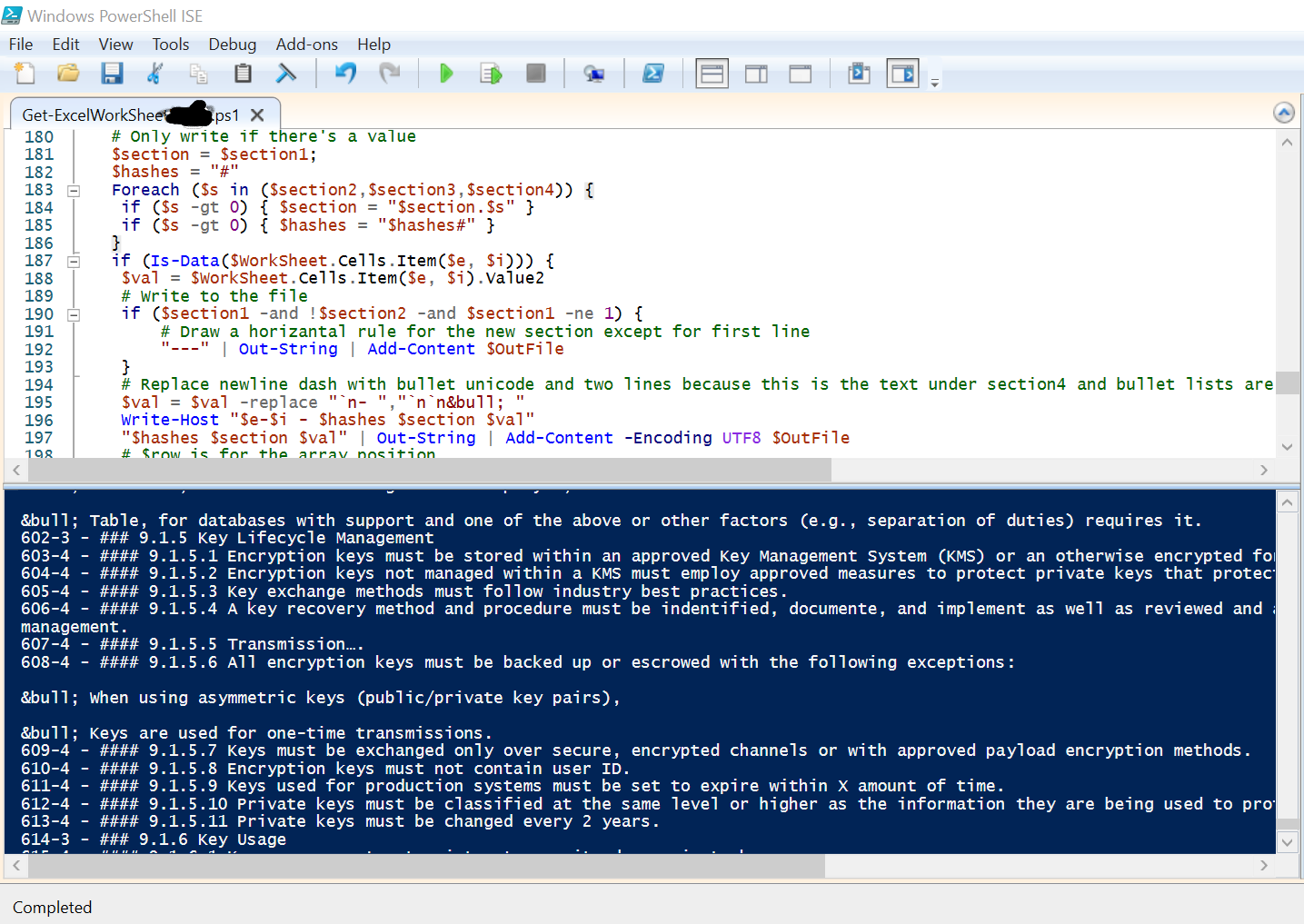
The bottom of the screen capture shows the Write-Host output I’m using to troubleshoot and show progress at it processes the spreadsheet.
Hashes are inserted, reflecting the level in the section heading hierarchy. Because of some Pandoc limitations, I avoid simply using dashes for bullet points. Instead, I add the Unicode bullet character. This approach leads to it being treated as a paragraph by Pandoc and properly drops it under the section with indentation.
This also allows me to do additional search and replace tasks as I extract and process the data for the Markdown output. For example, we used a convention of “…included in this section (X.X)” within the text. Usually this is found in a sub-section. As I track where we are in the graph, I can know that while this language is in 1.2.3, for example, I can replace X.X with 1.2.
Once the PowerShell processes the spreadsheet into Markdown (.md extension), we can run the Pandoc command.

This tells Pandoc to use –reference_doc (the template) to output standards.docx (-o argument) and standards.md as input. Also note the –toc argument that produces a table of contents at the top of the document.
The following shows the Markup in an editor with preview on the right:
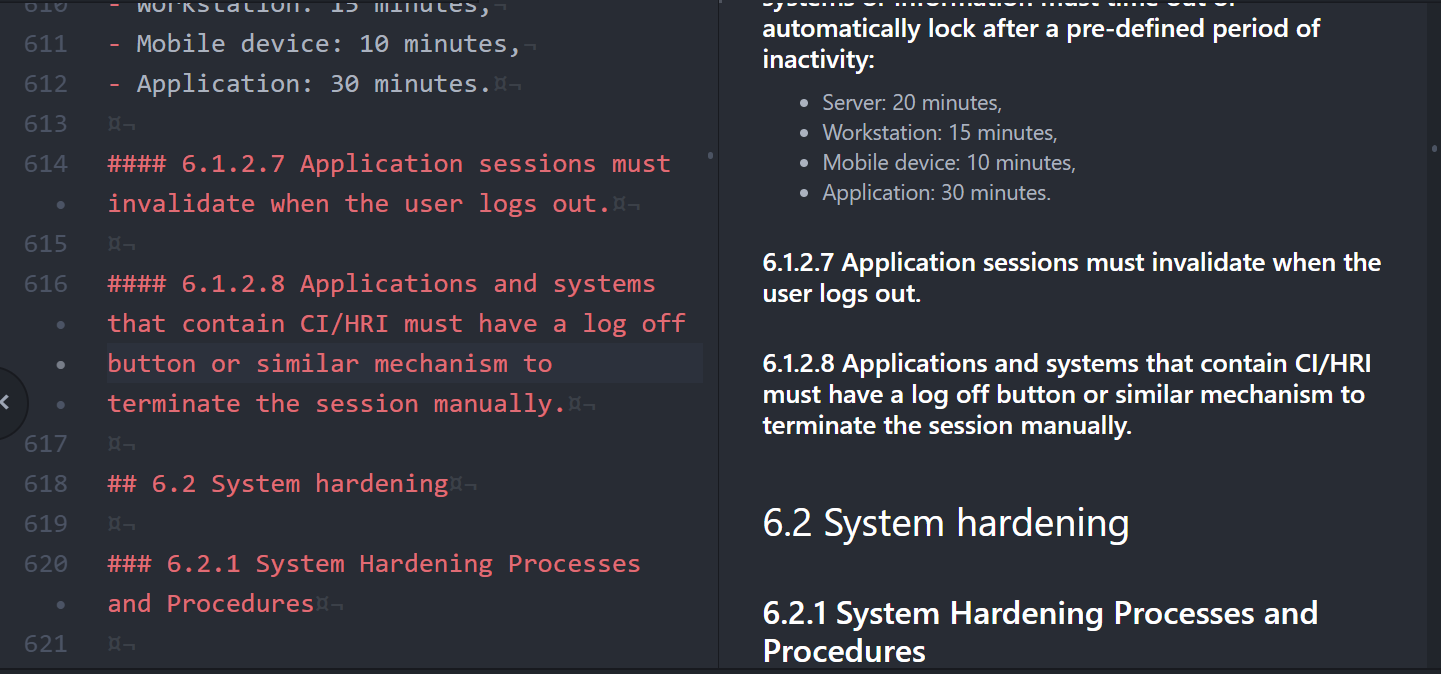
The following shows a snippet of the document that is output from the above command line:

Note the styling that is included, with colors, etc.
The following shows the table of contents that’s produced:

This code is very specific to the method I’m employing for this client, but will be adapted for different inputs, section level depth, etc. as-needed. Also, if you’re a PowerShell expert, I’ll gladly accept recommendations for improvement.
Github
Just a short note about using GitHub. For my purposes, I use this as a repository for my markdown and scripts. For the client, I will be using Azure Devops. This essentially covers much of what you could get from a document management system. Not only does this provide the versioning and collaboration capabilities that will be useful, it doesn’t assume how I will edit anything, whether it’s markdown or scripts. When I’m on my Chromebook, I use Caret. When I’m on my Linux Manjaro workstations, I use Atom. When I’m on the client-provided workstation, I use Atom for Windows. Pulling, committing and pushing are either command-line based or use integrated Git tools in Atom.
Conclusion
Yes, this all could all be done with a document management system, a fancy GRC tool, etc. I designed and developed a system for generating mortgage documents with precise federal, state and local markup using a well-known document management system, a rules engine, and a whole lot of Java and XSLT. I’m familiar with the enterprisey approach.
However, I’ve worked for some of the biggest companies in the world as well as small companies with a few hundred or even five employees. I’m sure I’m not alone in observing that when people buy these best-of-breed tools that they tend to use only a fraction of what the tools can do. It’s often a mentality where you buy the best and then hope to discover how it can serve the needed processes later. Of course, this is a very bad idea and just plain wasteful as the top tools tend to be quite expensive to license and you’re left with the ongoing challenge to find anyone who can develop and manage them.
It’s not an either-or equation with the approach I describe in this article. If you want to load this into your document management system, I can render the output accordingly. I can extract the content from any document management/workflow system and process it just the same.
If your company is talking Devops or, even more interestingly, if it is talking DevSecOps, this is an approach that I think will be quite compatible with processes you already have or want to have in place.
My client can continue to mange his standards language in Excel and I’ll leave him with the tools to generate them for whatever publishing solution he requires.
This approach will allow me to serve my clients for policy and standards documentation with an incredibly fast turnaround.
